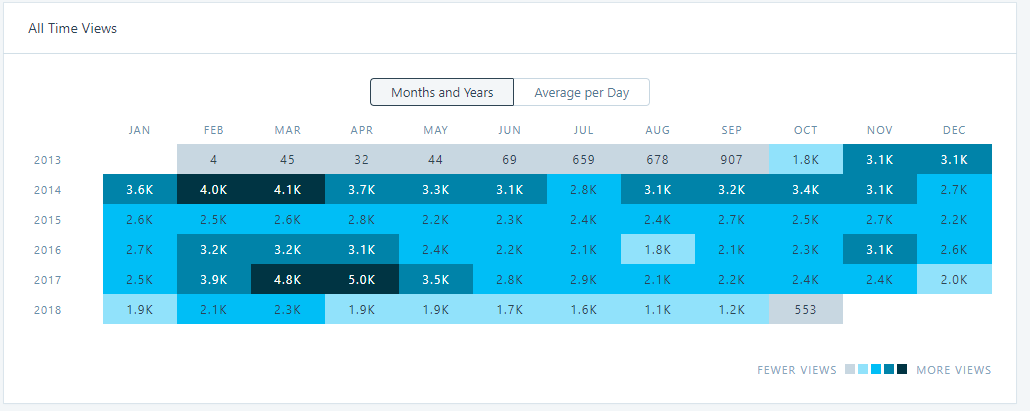
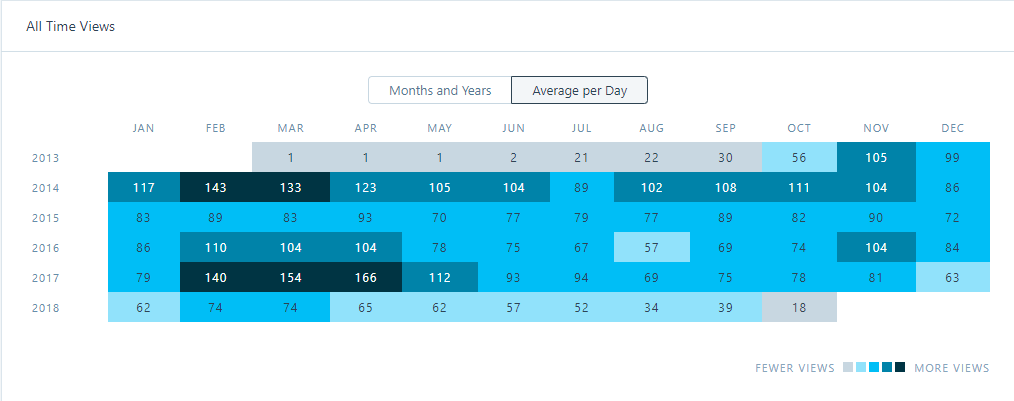
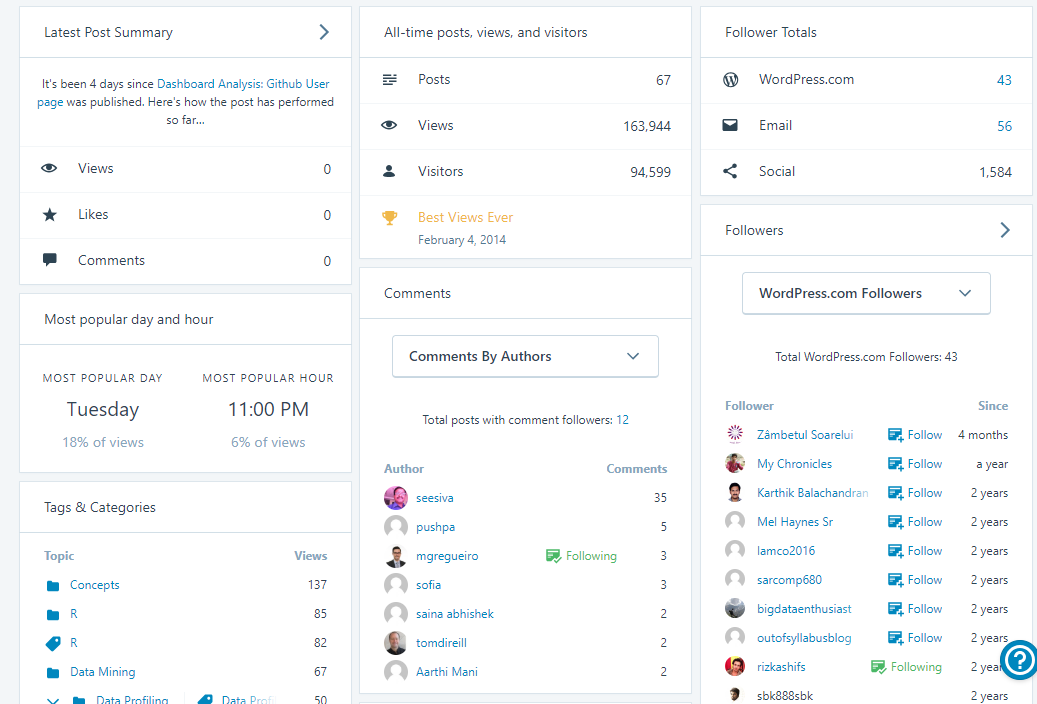
Typically Google Pay transactions are not easily analyzed. Google Pay has different flavors in different countries the capabilities of the app varies. If you want to analyze your spending in
In this post, we’ll explore how to automate the process of scraping and analyzing your Google Pay activity using Python. By the end of this post, you’ll be able to extract transaction data, categorize transactions, and save the data for further analysis.
Prerequisites
Before we begin, make sure you have the following prerequisites:
- Basic knowledge of Python.
- Familiarity with HTML.
- Python libraries: BeautifulSoup and Pandas.
You can install these libraries using pip:
pip install beautifulsoup4 pandasThe first step is to download your Google Pay activity as an HTML file. Follow these steps:
Step 1: Download Your Google Pay Activity
- Open the Google Pay app on your device.
- Navigate to the “Settings” or “Activity” section.
- Look for the option to “Download transactions” or “Request activity report.”
- Choose the time frame for your report and download it as an HTML file.
You can also look at the video.
Step 2: Parsing HTML with BeautifulSoup
We’ll use BeautifulSoup to parse the downloaded HTML content. Here’s how to do it:
from bs4 import BeautifulSoup
# Load the downloaded HTML file
with open('My Activity.html', 'r', encoding='utf-8') as file:
html_content = file.read()
# Parse HTML content
soup = BeautifulSoup(html_content, 'html.parser')
Step 3: Extracting Transaction Data
The Google Pay activity HTML contains transaction data within <div> elements. We’ll extract this data using BeautifulSoup, In this step we found the outer cell based on style and also leverage the regular expressions to extract the various transactions in Google Pay including “Paid, Received and Sent”.
# Find all outer-cell elements
outer_cells = soup.find_all('div', class_='outer-cell mdl-cell mdl-cell--12-col mdl-shadow--2dp')
action_pattern = r'(Paid|Received|Sent)'
# Extract and store the action (Paid, Received, Sent)
# Iterate through outer-cell elements
for outer_cell in outer_cells:
# Find content-cell elements within each outer-cell
content_cells = outer_cell.find_all('div', class_='content-cell mdl-cell mdl-cell--6-col mdl-typography--body-1')
action_match = re.search(action_pattern, content_cells[0].text)
if action_match:
actions.append(action_match.group(0))
else:
actions.append(None)Step 4: Handling Date and Time
Extracting the date and time from the Google Pay activity HTML can be challenging due to the format. We’ll use regular expressions to capture the date and time:
date_time_pattern = r'(\w{3} \d{1,2}, \d{4}, \d{1,2}:\d{2}:\d{2}[^\w])'
date_time_match = re.search(date_time_pattern, content_cells[0].text)
if date_time_match:
dates.append(date_time_match.group(0).strip())
else:
dates.append(None)
Step 5: Categorizing Transactions
To categorize transactions, we’ll create a mapping of recipient names to categories. This would help to consolidate the expenses and analyse the expenses by category.
recipient_categories = {
'Krishna Palamudhir and Maligai': 'Groceries',
'FRESH DAIRY PRODUCTS INDIA LIMITED': 'Milk',
'Zomato':'Food',
'REDBUS':'Travel',
'IRCTC Web UPI':'Travel',
'Bharti Airtel Limited':'Internet & Telecommunications',
'AMAZON SELLER SERVICES PRIVATE LIMITED':'Cloud & SaaS',
'SPOTIFY':'Entertainment',
'UYIR NEER':'Pets'
# Add more recipient-category mappings as needed
}Step 6: Automating Categorization
Now, let’s automatically categorize transactions based on recipient names and prepare the data frame:
# Map recipients to categories
df['Category'] = df['Recipient'].map(recipient_categories)
# Reorder columns
df = df[['Action', 'Recipient', 'Category', 'Account Number', 'Amount', 'Date', 'Month', 'Year', 'Date and Time', 'Details']]Step 7: Saving Data to CSV
Finally, we’ll save the extracted and categorized data to a CSV file:
# Save the data to a CSV file
df.to_csv('google_pay_activity.csv', index=False, encoding='utf-8')Now, you have your Google Pay activity data neatly organized in a CSV file, ready for analysis!
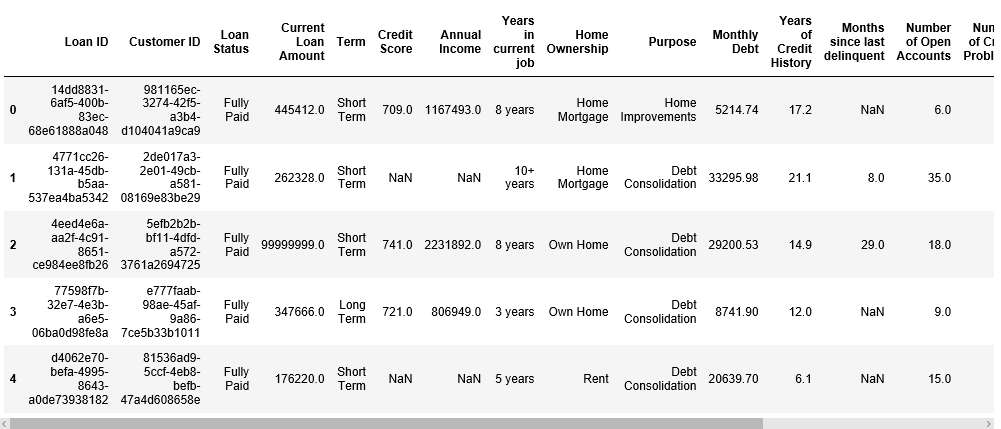
Outcome
You can see that mapping has worked automatically and CSV has been generated. Sample output shared here for quick reference.

Conclusion
In this post, we learned how to automate the process of scraping and analyzing Google Pay activity using Python. By following these steps, you can easily keep track of your financial transactions and gain insights into your spending habits.
Feel free to share your comments and inputs.